Block-Based Encrypted Cloud Backup with Duplicati 2.0
I am an infrastructure guy (by heart – and a developer by nature). As such, topics like maintaining my own webserver (which I don’t – yet) or configuring backup deeply fascinate me. I am also mildly paranoid with regards to the safety and, especially as of late, the privacy of my data. That makes finding the perfect backup strategy a very interesting occupation, indeed.
I only recently realized I was being incredibly stupid for storing my source code, my most valuable asset, in a cloud version control system. Oh, the connection was SSL-secured, of course (whatever that still means today), but the files were eventually stored naked and unencrypted on some disk. Anybody capable of hacking the company providing the version control service or even the company hosting the physical servers could just copy everything I had worked years to create. Stupid mistake. The same applies to all unencrypted cloud storage hosting data of any value. Stupid. Mistake.
To make this clear: I am not a technology disbeliever or cloud sceptic. I simply am a realist. We all still need to learn a lot about how to deal with these great new technologies in such a way that they help us live better lives and not kick us in the ass for having disobeyed some security postulation largely unknown to the majority of the population.

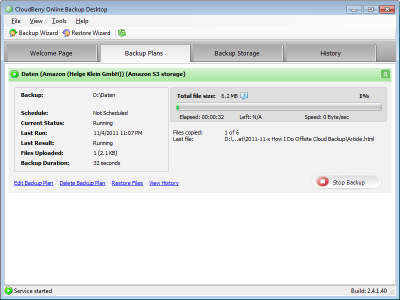
Back to the topic announced in the title. I had already used encrypted block-based backup to a cloud service: I have been backing up all my personal and professional data to Amazon S3 with Cloudberry Backup for a long time and I am very happy with it (read more here). However, with the cloud version control system gone my second backup target was no more and I felt I needed a replacement – after all, only having one local and one cloud backup cannot be enough, can it (did I mention paranoid?). I wanted another cloud backup, and I wanted it to be a real fail-safe. In other words, it was to be the last resort should Cloudberry Backup not be capable of restoring data, or if Amazon S3 somehow lost my data. That means I was looking for: another backup program and another cloud to back up to.
Of course all my other requirements for a backup program still apply:
- High-quality software, must not negatively impact my system’s performance (this probably rules out 80% of all backup programs)
- Native support for a cloud provider I could be happy with that is not Amazon
- Block-based transfer of changed parts only
- Client-side encryption
There are not many programs that meet these conditions. In fact, I only found one (in addition to Cloudberry Backup): Duplicati 2.0. Although still in beta and command-line only as of yet it promises to be just the right evolutionary step from version 1.x which had a simpler, not block-based, engine, requiring full backups every now and then.
Looking at the range of backup targets Duplicati 2.0 supports, it finally hit me what the perfect location for this secondary backup is: my website. Putting encrypted data there via FTP is no worse than putting it on Azure or some other cloud. But since I have the space anyway, it comes at no additional cost.
Configuration
There is no GUI for Duplicati 2.0 available yet, but setting up a backup job on the command line does not require more than this:
Duplicati.CommandLine.exe backup ftp://username:[email protected]/subdirectory --passphrase=DataIsEncryptedWithThis "C:\Backup Dir 1" "C:\Backup Dir 2"
That backs up two different directories on drive C:, AES-256 encrypting all data with the given passphrase. The files are combined into compressed containers of roughly 50 MB each which are stored on the FTP server specified.
Exclusions
You will likely not want to back up everything in these specified directories. In my case, that was most definitely true. Visual Studio source code directories contain all kinds of (very) large files that can be recreated from the code easily and need not be included in a backup. Add the following to exclude all kinds of superfluous compiler files:
--exclude=*\ipch\* --exclude=*\Debug\* --exclude=*\Release\* --exclude=*.sdf --exclude=*.suo --exclude=*.opensdf
Finally, you might want to have a log of what Duplicati actually did. Add this to the command line:
--log-file=Duplicati-backup.log --log-level=Information
Repair
If network connectivity is lost while a backup is running it may happen that the locally recorded state differs from reality (the files on the target server). Duplicati detects this when running the next time and asks for the repair command like this: Found 1 remote files that are not recorded in local storage, please run repair.
When that happens you can initiate the repair with the following command:
Duplicati.CommandLine.exe repair ftp://username:[email protected]/subdirectory --passphrase=DataIsEncryptedWithThis --log-file=Duplicati-repair.log --log-level=Information
Resetting the State
Duplicati keeps a local database of the files backed up. When you delete everything in the target and restart Duplicati you will find out about that: it refuses to work, asking for the repair command. In that case deleting the locally kept state is probably the best solution: just delete the directory %AppData%\Duplicati.
What is Missing
The one thing that I am still missing in Duplicati 2.0 is – no, not a GUI, although that would be nice – a full log. The log generated with the parameter mentioned above only has metadata (so-and-so-many files processed etc.), but it does not have the names of each processed file. I want that – to be able to check what the software did (did I mention paranoid?).



3 Comments
Hi Helge,
It’s been over a year now since this post. Are you still using Duplicati?
You can use the –verbose commandline option to have it output every filename it encounters.
And, btw, there is a UI now :)
Great thanks!