Splunk Accelerated Data Models - Part 2
- Logs & Metrics
- Published Oct 29, 2015 Updated Apr 19, 2025
This article is based on my Splunk .conf 2015 session and is the second in a mini-series on Splunk data model acceleration. Make sure to read part 1 first.
Under the Hood
HPAS Population
The high-performance analytics store (HPAS) is populated by scheduled searches that run every 5 minutes. The HPAS spans a user-defined time range. Old events are purged automatically by a maintenance process that runs every 30 minutes.
Populating Searches
One auto summarizing search is added to the scheduler per data model object. These searches have a low priority and the total number of them is limited. This can be a problem if your data models have many objects and/or your Splunk instance is underpowered. If the summarizing searches cannot be run as often as they should the data model may become stale.
The following two settings in limits.conf can be used to tweak how many auto summarizing searches are allowed to run:
- max_searches_perc: Percentage of system-wide concurrent searches the scheduler can run. Default: 50
- auto_summary_perc: Percentage of scheduler searches to be used for auto summarization. Default: 50
With the default values only 25% of all concurrent searches are available for data model acceleration!
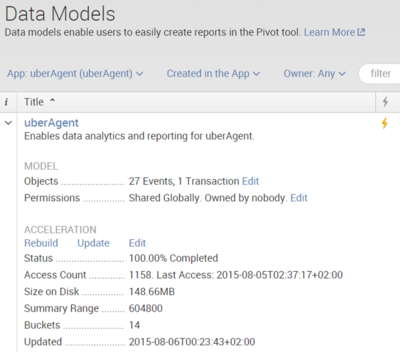
Checking Acceleration Status
A data model’s acceleration status can easily be checked from the UI by navigating to Settings > Data Models and clicking the little arrow next to a data model’s name:
To check the acceleration status from a search use the following:
| tstats summariesonly=t min(_time) as min,
max(_time) as max count from datamodel=uberAgent
| eval "Start time"=strftime(min, "%c")
| eval "End time"=strftime(max, "%c")
| eval "Event count"=count
| fields "Start time" "End time" "Event count"
This search will return the dates of the earliest and latest events in the high-performance analytics store (HPAS). Note that by adding the parameter summariesonly=t we only search the HPAS.
Data Models and Apps
Data Model Definition
A data model definition is stored in a file called modelname.json in the directory $SPLUNK_HOME\etc\apps*appname*\default\data\models.
The data model definition resides on the search heads and is sent to the indexers as part of the replication bundle.
Important: If the data model definition exists on multiple independent search heads, multiple copies of the HPAS are created! This unecessarily increases indexer CPU load and disk size requirements. This warning applies to independent search heads only, not to search heads in a cluster.
Enabling Acceleration
To enable acceleration for an app’s data model add the following to the app’s datamodels.conf:
[uberAgent]
acceleration = 1
acceleration.earliest_time = -1w






Comments