Persistent VDI in the Real World - Storage
- Citrix/Terminal Services/Remote Desktop Services
- Published Dec 5, 2013 Updated Dec 6, 2013
This is the second article in a multi-part series about building and maintaining an inexpensive scalable platform for VDI in enterprise environments.
Previously in this Series
I started this series by defining requirements. Without proper requirements, everything else is moot. Remember that we are looking at running typical enterprise desktop workloads, we are trying to centralize desktops and our primary desktop hosting technology is multi-user Windows, aka RDS/XenApp.
Since we already have stateless desktops with XenApp we chose to make the VDI machines persistent. We also selected the 64-bit version of Windows over 32-bit because that enables us to use the same image for both physical and virtual desktops.
Storage - Shared or Local?
One of the most important architecture decisions is where to store the virtual machines: in some sort of shared storage, accessible by all virtualization hosts, or locally on each hypervisor.
 by [Jim](http://www.flickr.com/photos/imjustsayin/) under [CC](http://creativecommons.org/licenses/by/2.0/)")
Shared Storage
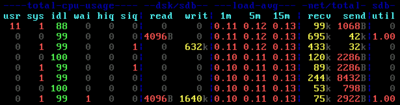
Shared storage typically means SAN, which in turns means expensive. What do you get for all that money? Certainly breathtaking speed, right? Well, not really. Traditional SANs are actually not that fast, especially not if they are based on magnetic disks only. And there is one really big problem many people are not aware of: IOPS starvation.
IOPS are the one thing you cannot have enough of. More IOPS directly translate to a snappier end user experience. The opposite is also true: poor IOPS performance in the SAN invariably causes hangs and freezes on the virtual desktop.
With many VMs competing for resources, a SAN is susceptible to denial of service conditions where a small number of machines generate such a high load that the performance is severely degraded for all. The answer is quality of service, where each VM gets guaranteed minimum and maximum IOPS values and is allowed the occasional burst. However, when implementing QoS great care must be taken not to create a condition where IOPS distribution across machines is fair but end user experience is equally bad for all.
In addition to these technical aspects there is the administration side of things. If you ask a typical SAN admin how many IOPS he can guarantee for your VDI project you may not get a satisfatory answer. And nothing stops him from putting more workloads on his box after your PoC is long over. Heck, the exchange admin, whose machines are in the same SAN as yours, could decide it is time to ugrade to a newer version which coincidentally generates twice as many IOs as before, tipping the delicate balance and causing IOPS starvation for all.
To summarize: shared SAN storage is expensive and you, the VDI guy, are not in control. Stay away from it.
Local Storage
The logical alternative to shared SAN storage is to use disks installed locally in the virtualization hosts. Even enterprise SAS disks are relatively cheap (at least compared to anything with the word SAN in its name), high load on one server does not impact the performance of any other host, and you, the VDI guy, are king. You can tune the system for VDI and make sure nothing else interferes with your workload.
Deduplication and IO Optimization
You still need many IOPS, though. And you need a lot of space (remember, we are talking about persistent VDI). With 40 VMs per server and 100 GB VM disks the net space required is 4 TB. That is enough to make us wish for deduplication. After all, most of the bits stored in the VMs are identical. They all have the same OS and, to a large extent, the same applications. Deduplication reduces the required disk space by storing duplicate blocks only once. This allows for huge space savings with persistent VDI: 90% and more is not unusual.
There are two ways deduplication can be implemented: inline or post-process. The former describes a technology where the data is deduplicated in memory before it is written to disk. The latter stands for a system where the data already stored on disk is analyzed and deduplicated after having been written. Both variants have their merits.
I have gained experience with Atlantis Ilio, which is an inline deduplication product. In a typical configuration it runs as a virtual appliance on each host. Each host’s disk IO goes through its Ilio VM, allowing Ilio to perform deduplication and additional IO optimization which reduces the IOPS going to disk to a certain degree. No postprocessing is required and data is stored in an optimized format. This happens at the expense of significant CPU and memory resources that need to be assigned to the Ilio VM and are not available to the actual workload. In other words, you trade CPU and RAM for disk space and IOPS.
Ilio Implementation Details
When implementing Ilio take the CPU and RAM requirements very seriously. Assign two vCPUs and reserve at least the equivalent of one physical CPU core for Ilio (more does not hurt). The same applies to RAM: better err on the safe side by adding a few gigabytes to the resulting value from the RAM calculation formula found in Atlantis’ admin guides.
One things that helps enough to qualify as a necessity is zeroing of deleted files. Think what happens on disk: files are created, written to and deleted all the time. However, the contents of the files, the actual blocks on disk, are not removed when a file is deleted, the data simply stays where it is. This gradually reduces the effectiveness of the deduplication. Luckily the solution is simple: from time to time zero the blocks on disk occupied by deleted files.
RAID Level and Number of Disks
Even with an IO optimization tool like Ilio you need as many disks as you can get. But you do not need much space. 1 TB per host is more than enough for 40 VMs. The number 40 is not being used randomly here, it marks the practical limit for contemporary two-processor servers.
Regarding the RAID level, we need something that is good at writes. RAID 5 is out of the question since each disk write causes two write IOs: one for the actual data, the other for the parity information. We use RAID 10 instead, which is the only standard RAID level that offers both good write performance and high capacity. Of course, RAID 10 is an active/passive technology where only half of the disks contribute to net space and IOPS performance.
IO performance increases with the number of spindles and the disks’ rotating speed. Choose 15K disks, and install as many of them per server as possible. Since we only need 2 TB of gross space we can buy the smallest disks available, which currently are 146 GB models. Typical mid-range servers like the HP DL380 can be configured to hold as many as 25 2.5" disks. Take advantage of that!
Why not use SSDs?
After all this talk about needing IOPS, and capacity not being of paramount importance the question is obvious: why not replace many magnetic disks with few SSDs?
Before answering let me tell you that I am a huge fan of the SSD technology. In my opinion SSDs are the best thing that happened to user experience in the last five years. Not having to constantly wait while using a computer is not something you are likely to give up once you have witnessed it yourself. And with the availability of drives that combine enterprise features (hint: consistent performance) with moderate prices SSDs are definitely ready for the data center.
So what is the problem? It is as sad as it is simple: support. Larger enterprises buy their server hardware from one or two vendors only. They have support agreements which cover most aspects of hardware malfunction. If there is a problem the vendor sends a technician to replace the failed parts and everybody is happy again. That works for SSDs, too, of course, but in order to be covered by the server vendor’s support you need to buy the SSDs from HP, IBM and the likes.
The actual root cause of the problem is that server vendors gladly sell you last year’s SSDs at a price that would have been high five years ago. Both HP and IBM charge roughly $3,600 for a 400 GB enterprise SSD. For something they do not manufacture themselves but buy from someone else at a presumably much lower price and relabel in order to justify the hefty premium they are asking. It is only logical that this tactic does not help the you, the customer. The performance you get is not really great, as I found out in earlier tests.
Effectively, HP, IBM and the other big vendors are preventing wide-scale SSD adoption by forcing customers to buy overpriced products that potentially deliver sub-par performance. If you know a way out of this please let us all know by commenting below.
Conclusion of Part 2
With SAN vendors being what they are, shared storage is just too expensive. At the same time it is dangerous because at the first sign of a problem the finger-pointing is going to start (which you already know from your interaction with the network guys). You want to avoid inviting another party to the game. So local storage it is. In any case, you need some kind of deduplication technology to make persistent VDI work. Sadly, server vendors prevent us from using SSDs unless price is not much of an issue. Even then performance should be double-checked.
In the next installment of this series I will explain how to size your VDI servers. Stay tuned!





Comments