How to Process Terabytes – per Day (or: my account of Splunk .conf 2013)
Processing several terabytes of data per day is not too uncommon and easily possible with Splunk – that is one of the many things I learned at .conf 2013 in Las Vegas.
![]()
With more than 1,800 attendees the conference has grown more than 100 % year over year. The Cosmopolitan hotel was at the brink of capacity and a move to the bigger MGM Grand is required for 2014. That demonstrates quite impressively the success of Splunk, the end of which is nowhere near to be seen. Splunk today is a bit like Microsoft in the early ’90s.
Although Splunk already has many of the really big enterprises as customers, most of these use it primarily for log management and security auditing. There is tremendous potential for future growth because Splunk is really so much more: a framework for working with any type of machine data. That data need not come from a log file, it may just as well be generated by a user experience monitoring product like uberAgent.
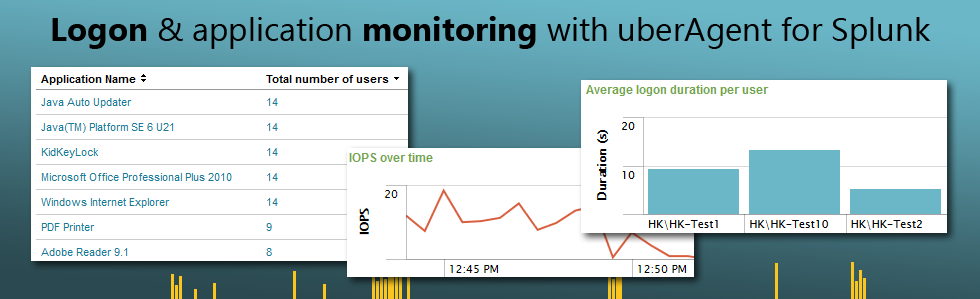
When companies start to use Splunk, they typically start with a single use-case. But news of the very capable new platform often spreads by word of mouth from one department to the next, and usage of the platform gradually increases as does the diversity of the data types indexed.
Indexers
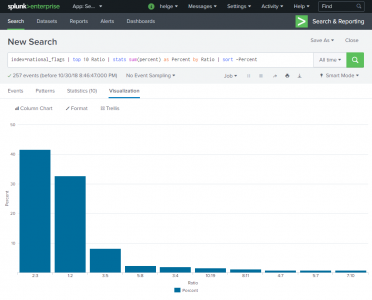
Getting a bit more technical, Splunk recommends having one indexer per 100 GB of daily data volume. That is already a lot, but much higher values are easily possible by scaling out: adding additional indexers is all that needs to be done. The incoming data is automatically distributed amongst all indexers. The largest installation I personally heard of includes 100 indexers and processes several terabytes per day.
In installations with many indexers, all indexes are spread across all indexers, by default. For large indexes that makes a lot of sense, but small indexes might better be limited to a subset of all indexers, to avoid hitting dozens of servers with searches that can easily be handled by a handful.
Indexers typically are commodity dual-processor servers. Splunk’s RAM usage is not high, 16 GB per machine is often enough. It is heavy on the disks, though, generating write IOPS at index time and read IOPS at search time. Consequently, Splunk recommends using local disks in a RAID 10 configuration. SSDs were not talked about, the cost is simply too high.
Dedicated search heads are only required with more than three indexers. In smaller environments, you use one of the indexers as search head, too. In large installations, it might make sense to dedicate a search head to jobs (creating a so-called job server).
Clustering
Clustering with Splunk really is index replication. You can define on how many different machines you want each event’s data to be stored and Splunk will do just that: after a new event has been processed by the receiving indexer it is sent to a second (or third, fourth…) indexer where it is stored, too. The cluster master is the instance that knows which data lives where.
The cluster master is the only single point of failure in this scenario. If it is unavailable things continue to work, but changes are not possible any more. It probably makes a lot of sense to have the master as a highly-available virtual machine, rather than employ a standby system to be activated manually in case of failure as recommended by Splunk.
Clustering incurs additional IOs and consequently reduces the indexing capacity per server. As a rule of thumb, a replication factor of 2 halves the servers’ capacity: you need twice as many of them. Considering this additional cost and the added complexity apparently many of the larger customers do not use clustering at all.
Archiving
Keeping historical data in a SAN or even on server local storage is expensive. If storage costs are an issue, determine required retention times for each indexed data type individually. It may well be possible that performance logs need only be searchable for 90 days while security logs might need to be searchable for 200 days. Since different data types typically go to different indexes retention can be adjusted granularly.
Splunk divides indexes into buckets, directories really. Buckets have one of several states: hot buckets are the ones being written to. When a hot bucket reaches a certain size or age, it is rolled to the warm stage, from where it goes to cold and finally frozen. Both warm and cold buckets are searchable, there is really no difference except optionally the storage location, which makes it possible to put older data on less expensive storage.
Once a bucket reaches the frozen stage it is deleted unless it is moved to an archive by script. It is important to note that the archive is independent of Splunk and not searchable. Also keep in mind that restoring archived data, although possible, is not easy. Instead of keeping all data forever, consider simply deleting frozen buckets after optionally exporting only the most relevant events to some other system.