Splunk Accelerated Data Models - Part 1
- Logs & Metrics
- Published Oct 22, 2015 Updated Apr 19, 2025
This article is based on my Splunk .conf 2015 session and is the first in a mini-series on Splunk data model acceleration.
Why Accelerate?
Have you ever seen this?
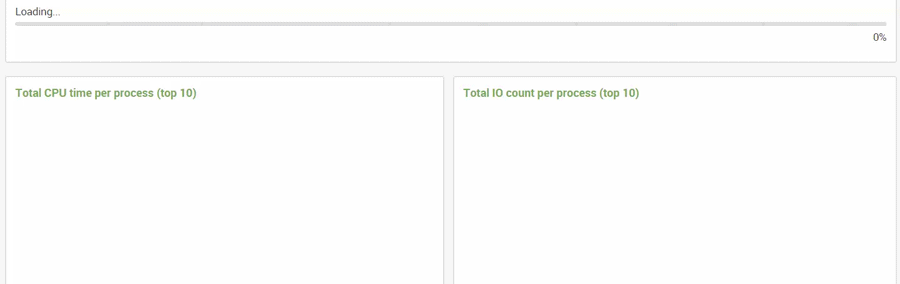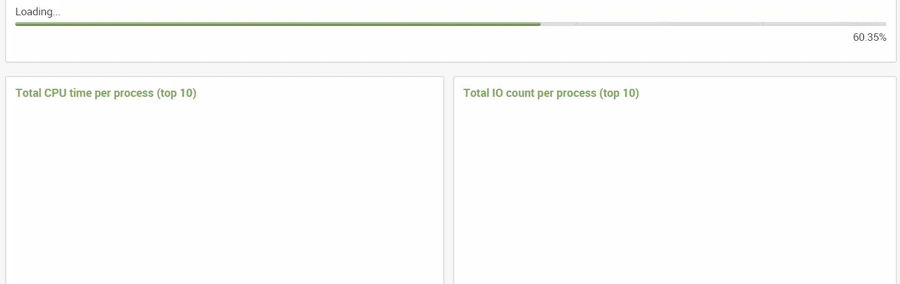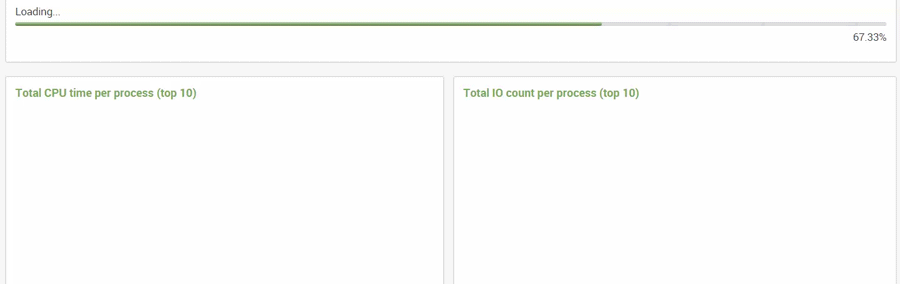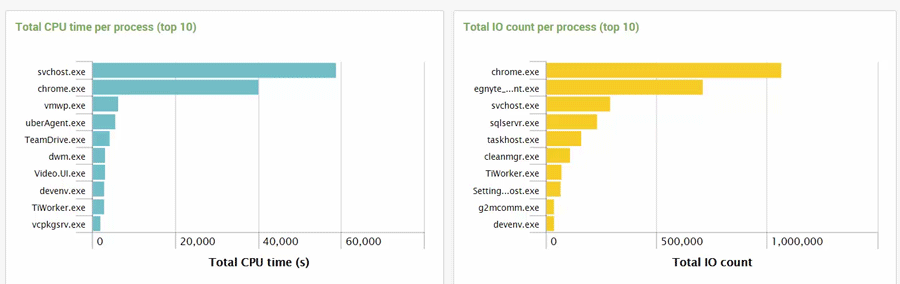
Splunk is great and very fast with needle in a haystack searches, e.g. find a specific keyword in millions of events. It is not so fast with searches that perform calculations on millions of events, e.g. the sum or average of fields.
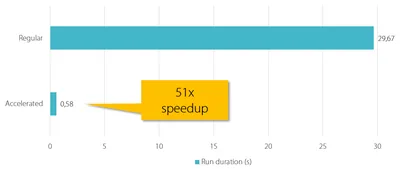
To determine the benefit of acceleration, we created two versions of an uberAgent dashboard that calculates a variety of metrics per process: one dashboard with regular searches, the other with accelerated searches. The 51x speedup is impressive:
How Data Model Acceleration Works
Data Models
A data model adds a second layer to your data. It does not remove classic Splunk functionality. A data model defines fields that create a schema.
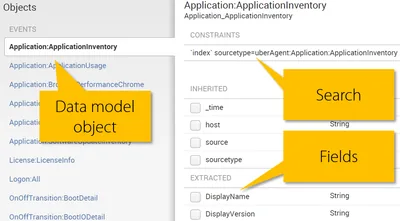
A data model can have one or more objects. Each object is powered by a constraining search that selects the events pertaining to the object. From those events any number fields can be extracted:
Acceleration
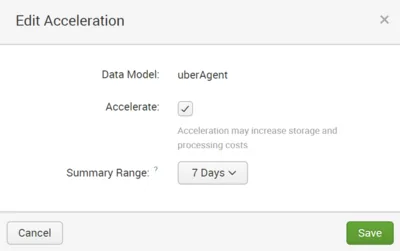
A data model can optionally be accelerated:
Field Extraction
Normally Splunk extracts fields from raw text data at search time. When a data model is accelerated, a field extraction process is added to index time (actually to a few minutes past index time). This greatly speeds up search performance, but increases indexing CPU load and disk space requirements.
Extracted data model fields are stored in the high-performance analytics store (HPAS). The HPAS is created on the indexers and resides in .tsidx files that are stored in parallel to the regular event buckets. The HPAS is not replicated in an indexer cluster because it can always be recreated from the raw data (please note that this may incur a significant load and may take a long time to complete).
Caveats
When creating a data model for acceleration keep in mind that of the different types of data model objects only those of type Root Event can be accelerated. Root Transaction and Root Search objects cannot be accelerated.
Once a data model is accelerated, it cannot be edited any more. During the development phase you will find yourself frequently switching acceleration off and back on. Note that when you do this the HPAS is discarded and later recreated which incurs additional load on the indexers.








Comments